I did some experiments with this small example game. My goal was to find effective AI settings; settings that would always lead to quick success. Last time, the AI did manage to beat the game after ~180 attempts – these settings were the starting point of a long testing session.
In this blog, I will go over the results of the experiments.
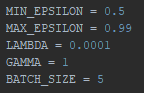
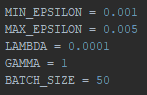
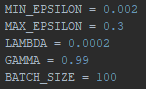
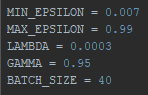 First, I repeated the final settings from the previous blog. As a reminder: Min- and Max-Epsilon indicate the range of the learning rate, lambda and gamma indicate values that influence the learning rate decay and the batch size is used to avoid overfitting (which would drastically impact the effectiveness of the AI).
First, I repeated the final settings from the previous blog. As a reminder: Min- and Max-Epsilon indicate the range of the learning rate, lambda and gamma indicate values that influence the learning rate decay and the batch size is used to avoid overfitting (which would drastically impact the effectiveness of the AI).
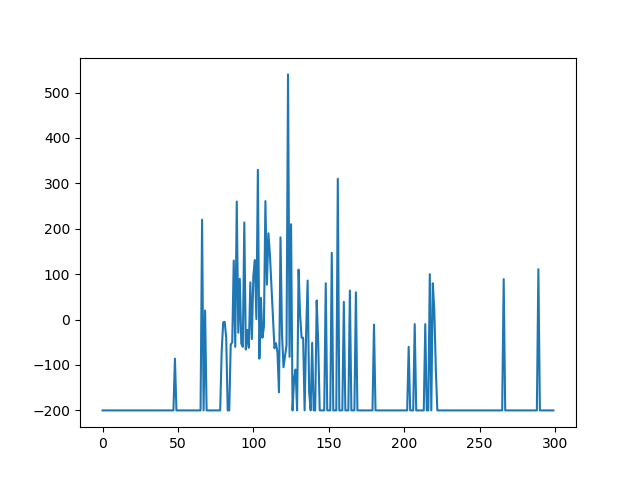
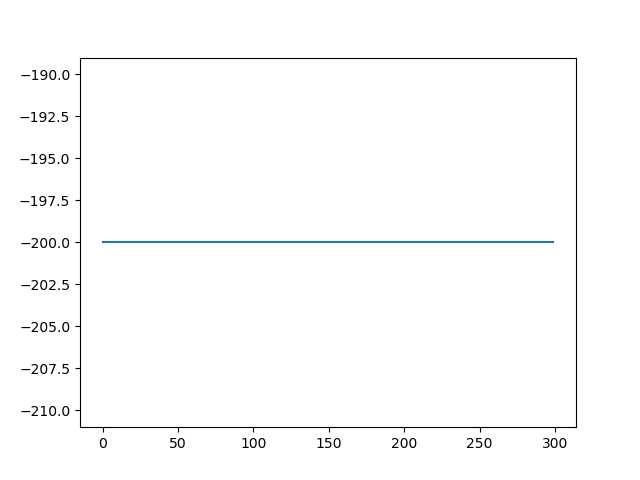
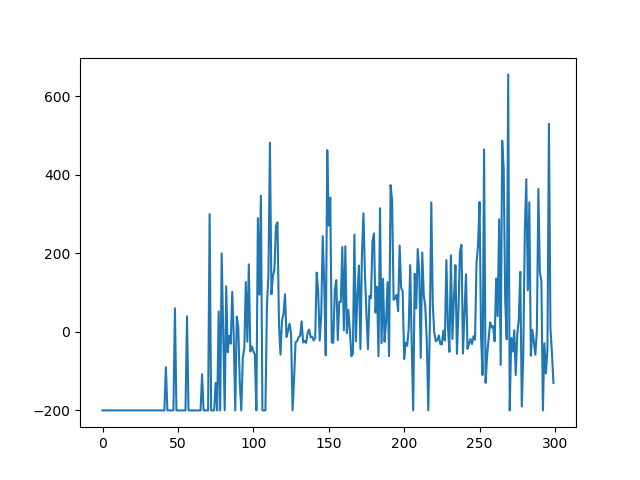
Although the AI manages to beat the game, it does so very inconsistently, as shown in Figure 1 (It counts as a win if the score is not -200).
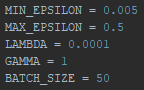
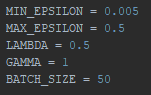
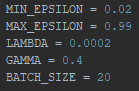 I quickly took a closer look on the Gamma variable, and decreased it to 0,4 (alongside with some other minor adjustments).
I quickly took a closer look on the Gamma variable, and decreased it to 0,4 (alongside with some other minor adjustments).
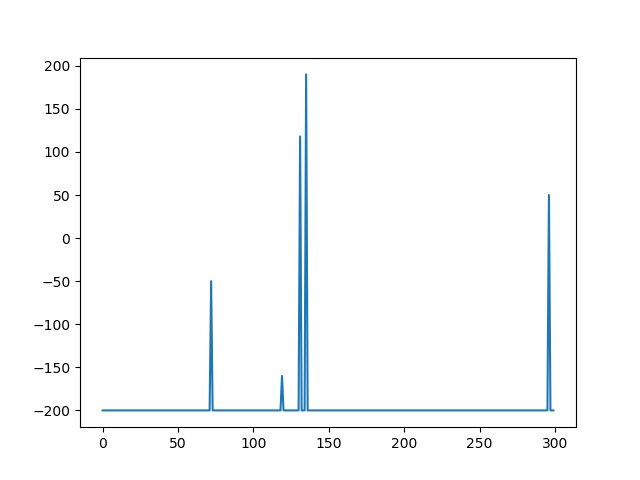
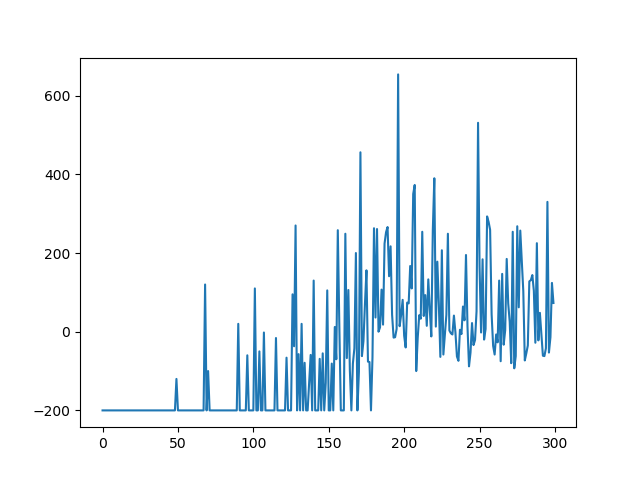
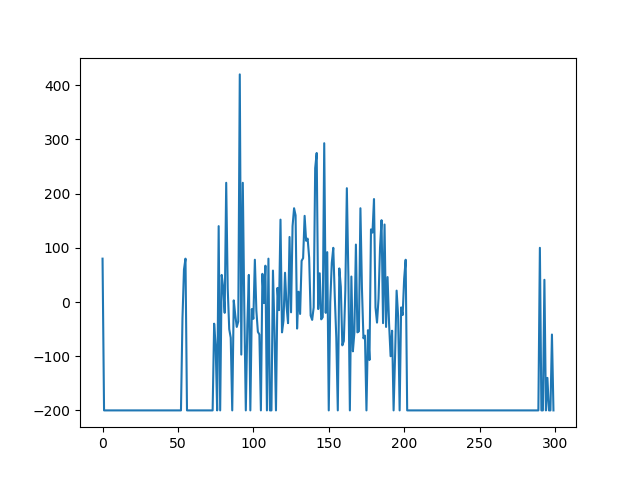
The low Gamma causes the AI to fail consistently, as shown in Figure 2. One possible reason could be that the learning rate decay may be flawed; causing the learning rate to drop too fast or not at all. I also tried the same settings with a batch size of 100, the results were the same.
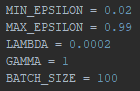
I maxed out the Gamma setting and tried again.
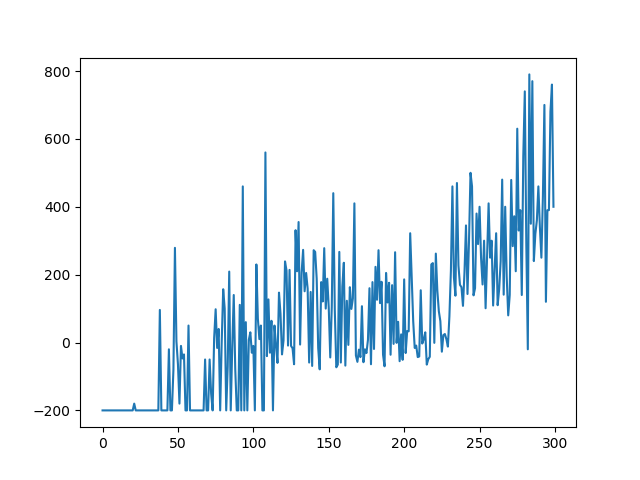
As shown in Figure 3, these results are great. The AI beats the game at first in attempt ~45 and never fails it again post 120.
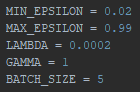 Out of curiosity, I decreased the batch size from 100 to 5.
Out of curiosity, I decreased the batch size from 100 to 5.
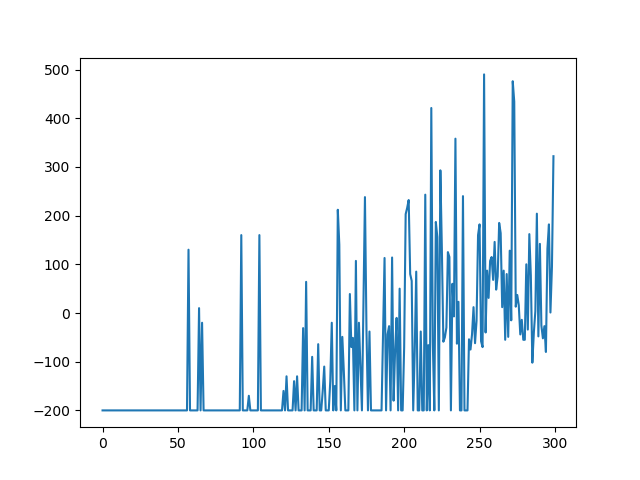
As shown in Figure 4, the impact of this change is significant. Although the AI actually beats the game as consistent as before, it does so a lot later than before.
 After the Gamma, I took a closer look on the learning rate min and max values. First, I set the mininum learning rate to 50%, which enables the AI to almost only explore its environment.
After the Gamma, I took a closer look on the learning rate min and max values. First, I set the mininum learning rate to 50%, which enables the AI to almost only explore its environment.
As shown in Figure 5, this change lead to the worst result possible. The AI did not manage to learn the mechanics of the game. There were some minor successes in repetitions of these settings, however, they resulted out of randomness.
 Next, I tried the opposite – low learning rates only.
Next, I tried the opposite – low learning rates only.
What an uplifting change. The AI had some minor successes in the first half of the 300 attempts and won consistently in the second, as shown in Figure 6. This shows that lower learning rates perform better, at least in this example game.
 I took it one step further and lowered the learning rate even more.
I took it one step further and lowered the learning rate even more.
As shown in Figure 7, the AI learns faster than before, but becomes rather incosistent towards the end. This might be because of randomness, however, the AI always showed this behavior in repetitions of these settings.
 Finally, I took a closer look on Lambda, the main factor for the learning rate decay. I increased it to a decent amount of 50%.
Finally, I took a closer look on Lambda, the main factor for the learning rate decay. I increased it to a decent amount of 50%.
The AI learns to beat the game quite early, just as before. There is one major difference though: after some time, the AI seems to forget how to play, as shown in Figure 8.
In conclusion …
- Low Gamma settings should be avoided.
- Too low batch sizes delay success.
- High learning rates allow for exploration rather than actual learning.
- Low learning rates show the best performances.
- High Lambda settings show a negative impact on the AI at later training stages.
 Putting these conclusions to the test, I did one final test.
Putting these conclusions to the test, I did one final test.
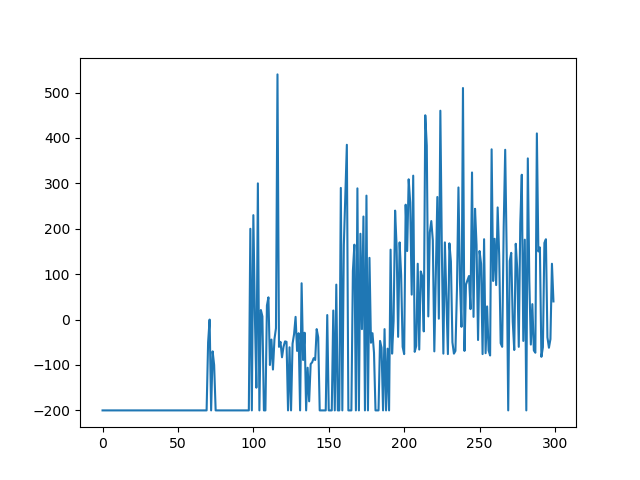
As shown in Figure 9, the AI starts to consistently win the game after attempt ~100. These results could possible be topped if the learning rate was set even lower, but I will leave it at that.