„A pole is attached by an un-actuated joint to a cart, which moves along a frictionless track. The system is controlled by applying a force of +1 or -1 to the cart. The pendulum starts upright, and the goal is to prevent it from falling over. A reward of +1 is provided for every timestep that the pole remains upright. The episode ends when the pole is more than 15 degrees from vertical, or the cart moves more than 2.4 units from the center.“ – Source: https://gym.openai.com/envs/CartPole-v0/
In this blog, I will describe the most important parts of the code and show some test results.
The code for this example can be found here: https://github.com/inoryy/tensorflow2-deep-reinforcement-learning
The code consists of two major classes – the model and the A2C-agent – and a simple training sequence.
The TensorFlow model used in this example has some interesting features:
- All layers in it are separated from execution, making it it easier to make changes
- There is no “input” layer – all incoming data (raw numpy arrays) is fed into the first hidden layer instead.
- It contains a helper method (i.e. an action sampling method that helps with making predictions)
- It works In eager mode: everything works from raw data
The A2C-agent has been described in theory in the previous blog. Basically, this state-of-the-art technology takes the role of the player. The goal of this agent is to improve in the game. It improves in the game by taking better actions. It takes actions by playing based on a policy. Thus, the actual goal of the AI is to improve its policy. This is achieved using the gradient descent method, which is implemented in form of a so-called loss (or objective) function. How can it be improved, exactly? This gets too complicated for this blog, but summarized there are three areas that should be considered for this: developing advantage weighted gradients, maximizing entropy and minimizing value estimate errors.
Tests
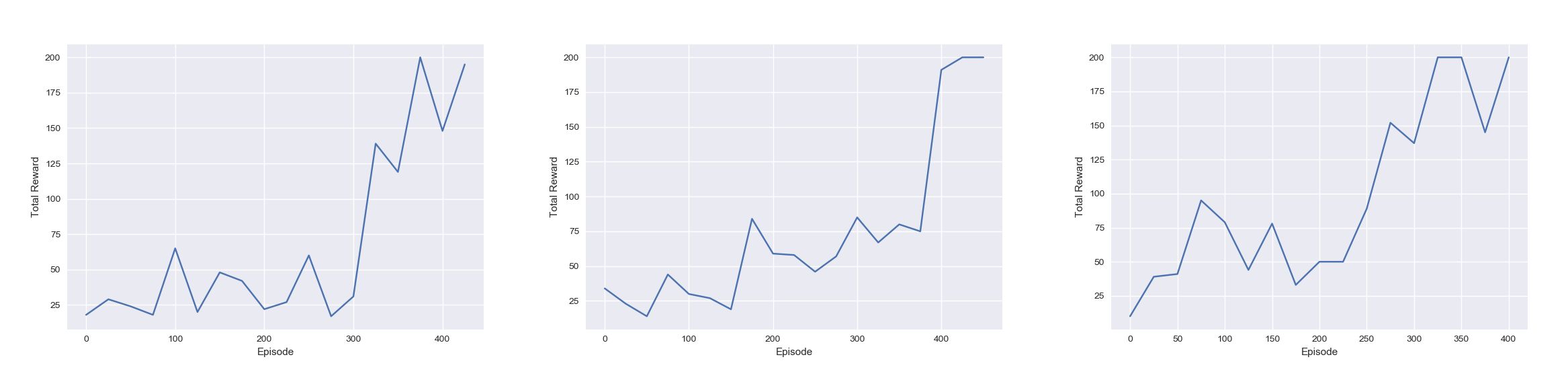
The three diagrams above show three different outcomes of some training sessions. On the X axis lies the number of attempts while on the Y axis lies the score of an attempt. In every run, the AI successfully managed to win the game – it even won consistently after ~350 attempts. When it comes to time, each run completed in around 3 minutes. Overall, the results were quite satisfying.
This example (the code and more information on the topic) can be found here in the source link below.
http://inoryy.com/post/tensorflow2-deep-reinforcement-learning/