This blog is about the policy-iteration method Proximal Policy Optimization (PPO).
Overview
PPO is a robust (cf. [Burda 2018]), data efficient and reliable policy gradient reinforcement learning algorithm, introduced by John Schulman et al. in 2017. The PPO algorithm was designed to adopt the benefits of another, similar method, Trust Region Policy Optimization (cf. [Schulman 2015]), while also being more general and simpler to implement (cf. [Schulman 2017]).
PPO is an actor-critic policy gradient method; a hybrid algorithm. This means that the AI adapts both a policy and a value function during the training phase. Typically, the policy and value functions are modeled with a neural network that provides the same initial parameters, but splits later, leading to individiual outputs, as shown in Figure 1.
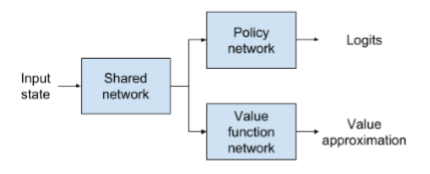
The actor-critic network takes the current state of the environment as input. The outputs includes both a vector with the same length as the action space (= amount of possible actions; the policy) and a single value (the approximated value in the current state). In its raw form, the action space vector is usually referred to as a logit.
The policy then chooses the next action by using a sampling approach called the Gumbel-Max trick (cf. [Maddison 2014]). It leads to the same results as sampling from a softmax distribution, however, the logits do not need to be softmax-transformed. Using this trick allows for calculating the entropy bonus, which requires un-transformed logits.
Entropy Bonus
The entropy bonus is a helper variable that influences the learning process. By maximizing the entropy bonus, the algorithm starts to discourage the policy to prematurely converge towards highly-peaked logits, which expands the exploration phase (cf. [Wu 2016]).
Why is prematurely converging towards highly-peaked logits not recommended?

First, assume a chart as displayed in Figure 2. The chart has an obvious minimum and maximum point. For explaining purposes, assume that the blue line displays the impact of a possible action, where the maximum is the most desireble outcome. The black line indicates the current state of the policy. What would happen in this situation?
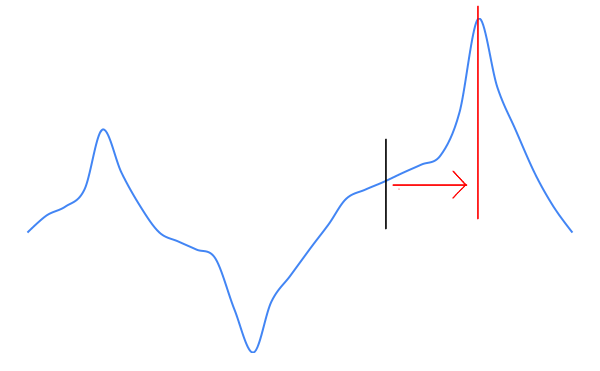
If the algorithm works, the policy would converge towards the peak, which means in this case that the policy moves to the right, as shown in Figure 3. This would be the best case scenario, since that is the maximum point in the chart.
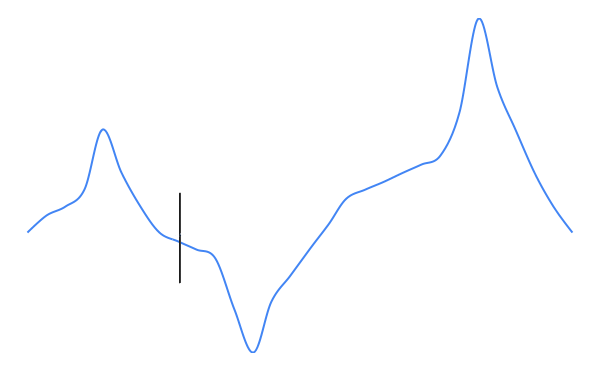
Now, assume the same situation except that the current policy is different, as shown in Figure 4. Assuming the same applied method, what would happen in this case?

The policy would converge towards the peak to its left, as shown in Figure 5. This is a problem, since the policy would never get even close to the actual maximum action.
This is why such a entropy bonus is nice to have. It also shows that exploration is very valuable when it comes to reinforcement learning.
Rollout and Learn
The PPO algorithm iterates between two phases: a rollout phase and a learning phase. In the rollout phase, a predefined number of actions are taken in the environment, based on the current policy. For each action cycle, the algorithm stores the input state with the corresponding action, probability of that action, the gained reward signal, the logit for the chosen action and the approximated value. The gained reward signal and the approximated value are then used to calculate a generalized advantage estimation (cf. [Schulman 2017]).
The generalized advantage estimation (along with the other stored values) is used for updating the policy and the value function (= the weights of the neural network) during the learning phase. After the learning phase is completed, the data is cleared and the method’s next iteration cycle, i.e. a rollout phase, starts.
Sources
[Burda 2018]
Burda, Yuri; Edwards, Harrison; Pathak, Deepak; Storkey, Amos; Darrell, Trevor; Efros, Alexei: Large-Scale Study of Curiosity-Driven Learning. In: CoRR abs/1808.04355 (2018). arXiv: 1808.04355. URL: http://arxiv.org/abs/1808.04355 (13/01/2020)
[Schulman 2017]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. “Proximal Policy Optimization Algorithms”. In: CoRR abs/1707.06347 (2017). arXiv: 1707.06347. URL: http://arxiv.org/abs/1707.06347 (13/01/2020)
[Wu 2017]
Wu, Yuxin; Tian, Yuandong: Training agent for first-person shooter game with actor-critic curriculum learning. ICLR 2017. https://openreview.net/pdf?id=Hk3mPK5gg (13/01/2020)
[Schulman 2015]
Schulman, John; Levine, Sergey; Moritz, Philipp; Jordan, Michael; Abbeel, Pieter: Trust Region Policy Optimization. In: CoRR abs/1502.05477 (2015). arXiv: 1502.05477. URL: http://arxiv.org/abs/1502.05477 (13/01/2020)
[Maddison 2014]
Maddison, Chris; Tarlow, Daniel; Minka, Tom: A* Sampling. In: arXiv e-prints, arXiv:1411.0030 (Oct. 2014). arXiv:1411.0030. URL: http://arxiv.org/abs/1411.0030 (13/01/2020)