Typically, the algorithm that an Reinforcement Learning (RL) bot is following is built around the reward function. In the previous Lost Chapters blog I mentioned Curriculum Learning: a method that has the purpose of improving the algorithm – and there are more performance improvers like that, which are today’s topic.
In this blog, I explain methods that improve an RL AI’s algorithm.
Masking out of Illegal Actions
When thinking of grid-like board-games like Chess, it is obvious to us that not all actions are allowed in any given state. For example, the rules of Chess forbid the pawn to be moved backwards.
It is possible for a RL algorithm to learn to distinguish between legal and illegal actions by returning a negative reward signal to illegal actions, however, this adds another dimension to the problem, which ultimately worsens the performance. One possible solution to solve the issue is to ‚mask out‘ illegal actions by setting their probabilities to zero. (cf. [Silver 2017])
Game Board Representation
A often used representation of a rectangular, grid-based game (like chess) is a tensor containing sparse, binary feature planes, as shown in Figure 1. The height and width represent the game board itself, and each feature plane in the tensor represents different characteristics of the game. An example of a common feature plane characteristic is the location of certain game pieces. (cf. [Gudmunsson 2018])

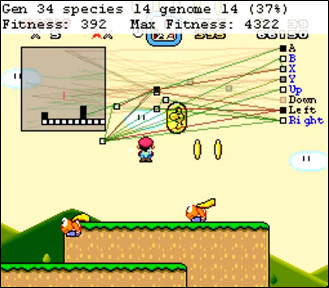
Looking back to MarI/O, we can see this method in action, as shown in Figure 2. In this example, white feature planes represent safe sprites while black feature planes represent enemies. In this case, the „game board“ is the current part of the level that is displayed on the screen. We can also see that the AI is connected with the game board representation: it uses it as a base for input decisions.
Evaluation Metrics
Depending on the game, an ‚ELO-rating‘ (cf. [Glickman 1999]) may be used to evaluate an self-playing agent. Unlike the reward signal, the ELO rating indicates the ’strength‘ of a player in the respective game. In modern online multiplayer games, the ELO indicator is typically used behind the scenes to optimize match-making algorithms, which improves the overall experience with the game. Applying this idea to RL, an in-game ELO rating could be used to evaluate the current training level of the AI.
In certain types of games that heavily depend on luck, like ‚Match-three‘ games such as Candy Crush, an ELO-rating may not be applicable. Also, a large score in such games does not necessarily mean that the game is won, as the level objective has to be fulfilled. Therefore, a overall win rate makes more sense than an ELO-rating. (cf. [Silver 2018])
Simply put, the reward signal indicates whether the AI wins or fails – but without metrics nothing indicates the actual skill of the AI.
Keeping track of an AI’s ELO or win rate could be used to reward-shift at the right times.
Sources
[Gudmunsson 2018]
Gudmundsson, Stefan; Eisen, Phillipp et al.: Human-Like Playtesting with Deep Learning. In: CIG.IEEE, (2018), pp.1–8.
[Silver 2018]
Silver, David; Hubert, Thomas et al.: A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. In: Science 362.6419 (2018), pp. 1140–1144.
[Silver 2017]
Silver, David; Hubert, Thomas et al.: Mastering chess and shogi by self-play with a general reinforcement learning algorithm. In: arXiv preprint arXiv:1712.01815 (2017).
[Glickman 1999]
Glickman, Mark; Jones, Albyn: Rating the chess rating system. In: CHANCEBERLIN THEN NEW YORK- 12 (1999), pp. 21–28.